

Welcome to the third post in my series on Testing AI. This series of posts and was inspired by the Ministry of testing 30 days of AI in testing event. This post takes a look at a specialist evaluation tool for Large Language Models, Trulens.
TruLens – Measure Quality and Effectiveness of Your LLM
TruLens is designed to be used with Python applications. To enable me to review it with my current Ollama setup I will be using LiteLLM. LiteLLM provides a simplified way to interact with my existing Ollama installation from a Python script.
What is TruLens?
Categorising TruLens in the mindset of traditional tools is difficult. In some ways it is a test tool, in others it is more like an observability tool. What TruLens is, is a way assess the quality of your LLM. TruLens does this by monitoring the input and output of your LLM and providing feedback methods across a range of metrics.

We’ll take a look at some of these once we have it setup and running.
Running TruLens locally
As I mentioned, I’ll be using LiteLLM to enable this. LiteLLM provides a python-based method of interaction with Ollama. The concept is overall similar to what I did in the last post with Playwright. We provide a prompt and make an assessment of the output. I have made my configuration available on GitHub. Note, I wouldn’t consider my implementation as a completed framework, instead consider it as an initial POC only.
Installing LiteLLM
Installation is as simple as running the below command.
pip install litellmAssuming you already have Ollama setup and configured you can then create a simple python script that looks like this to execute your prompts.
from litellm import completion
response = completion(
model="ollama/llama2",
messages = [{ "content": "Why is the sky blue?","role": "user"}],
api_base="http://localhost:11434"
)
print(response)Note, there is no assertion here. For the purpose of this post, we are just providing prompts to our LLM and not “testing” it. Instead, we will be using TruLens to assess the output later.
Configuring TruLens
I found many guides for doing this, and all a bit different depending on context. The below is just how I did it for the purpose of this post. Furthermore, you should treat the below code as a proof of concept, rather than a completed framework.
First, we need to install the TruLens package as part of our framework.
pip install trulens-evalNow we can update the python script to include TruLens.
from litellm import completion
from trulens_eval import Feedback, Tru, TruBasicApp
from trulens_eval.feedback.provider.litellm import LiteLLM
provider = LiteLLM(model_engine="ollama/llama2", endpoint="http://localhost:11434")
tru = Tru()
coherence = Feedback(provider.coherence_with_cot_reasons).on_output()
correctness = Feedback(provider.correctness_with_cot_reasons).on_output()
def llm_standalone(prompt):
response = completion(
model="ollama/llama2",
messages = [{ "content": "Only reply with words","role": "user"},
{ "content": prompt,"role": "user"}],
api_base="http://localhost:11434"
)
print(response)
return response
basic_app = TruBasicApp(llm_standalone, app_id="LiteLLM-Llama2", feedbacks=[coherence, correctness])
with basic_app as recording:
basic_app.app("Is the world flat?")
basic_app.wait_for_feedback_results()
tru.run_dashboard()
tru.get_records_and_feedback(app_ids=[])[0]The addition of TruLens to the code now provides us with a dashboard output. That dashboard will show us results for the correctness and coherence of our LLMs responses. It does this by calling Llama 2 to validate the responses. Similarly to the Playwright test framework, this is validating Llama 2 against Llama 2. It is possible the accuracy of our results will be limited by that. However, this is a limitaion of my setup, rather than the tool. TruLens offers access to various other evaluation methods too.
TruLens Dashboard
After completing some executions of prompts, I have a number of entries in my dashboard that I can review.
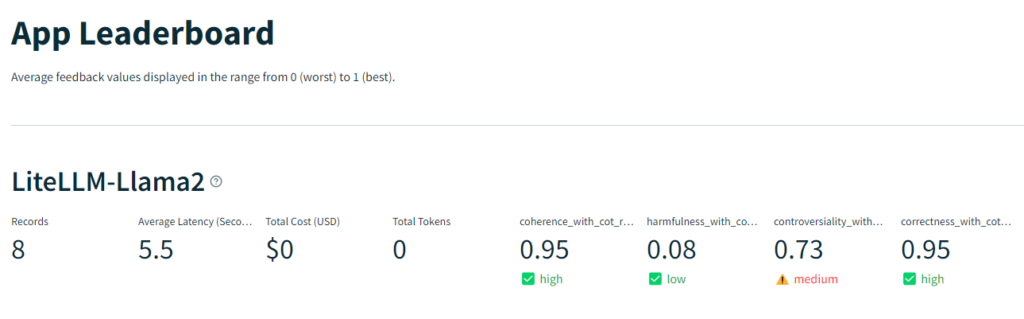
Here we can see the number of records (prompts), the average latency, and the scores for my various metrics – Coherence, Harmfulness, Controversiality, and Correctness.
We can dive deeper into those results and see the assessment for each prompt.
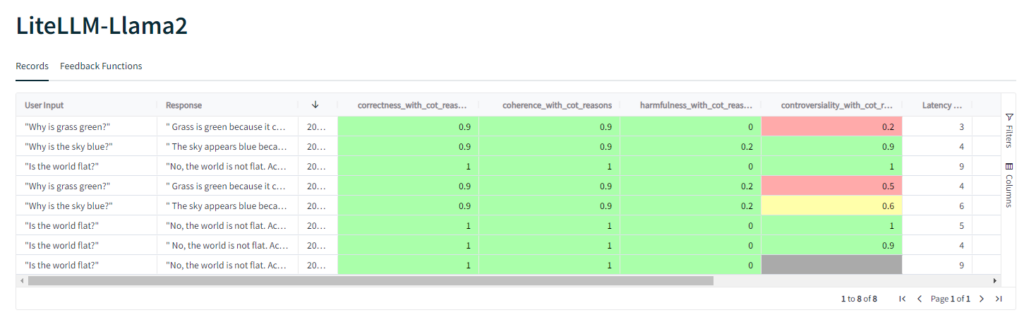
Some interesting results on the Controversiality metric! I think maybe this needs the
higher_is_better=falsesetting. Some surprising results all the same.
To determine the correct setting, I ran the same questions a few more times. Following that I was fairly certain the change was required, so made it, reset my database and ran more tests.
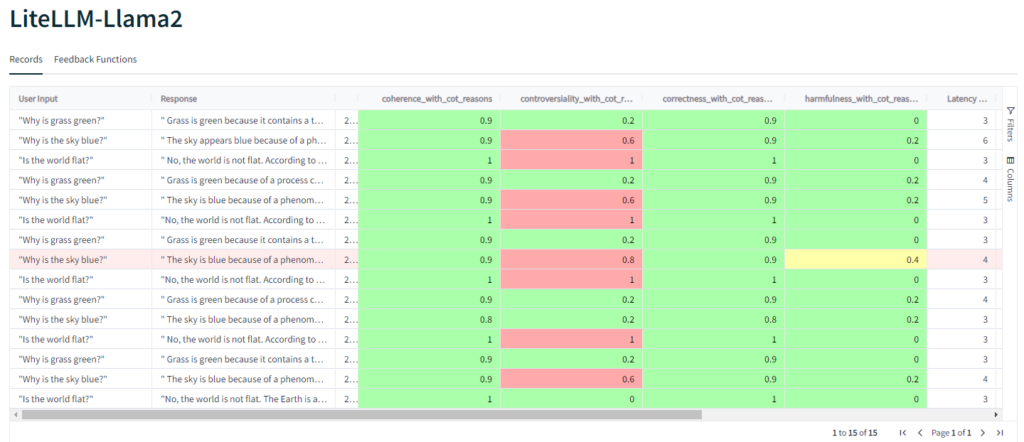
Still a surprising amount of controversy around the “why is the sky blue?” question, but the rest is far more in line with my expectations.
Evaluation Methods and Understanding Results
TruLens supports a broad spectrum of evaluation methods. From the “Generation-based” that I used above, to those provided by huggingface and OpenAI, amongst others. Each of these is provided by some form of LLM and carries the same issues as we have discussed in my last post. That is, we are reliant on an LLM to provide accurate results, and the associated cost of executing the additional prompts.
Given that TruLens is designed to be a pre-production tool, this is likely an acceptable cost. It would be possible to implement TruLens into a production system, but for cost reasons, I expect it would not be desirable to do so. I’ll be taking a look at LangSmith soon, which offers a production monitoring solution that is better suited for that purpose.
As well as providing scoring, a number of the metrics support provision of reasons for the scoring. This in addition to the score is a useful tool to understand the assessment and whether it is accurate or not. Unfortunately, at the time of writing I have been unable to view the reasons. They do not appear in the dashboard and are not stored in the sqlite database.
Summary
In the relatively short amount of time I have spent with TruLens, I have really come to like it. It is straightforward to configure and easy to understand. My only outstanding concern is that I am unable to see the reasons behind the scores. This is something I would dig into further before implementing in a workflow. Looking at the GitHub repo for the project, the team are responsive to issues. They also offer support via Slack so I imagine it would not be difficult to get this resolved.
Is it better than what I produced with Playwright? Absolutely. It offers many benefits over a home spun solution, and I am confident that any issues I experienced so far would be easily resolved with some more time spent working with TruLens.
Further reading
If you enjoyed this post then be sure to check out my other posts on AI and Large Language Models.
Subscribe to The Quality Duck
Did you know you can now subscribe to The Quality Duck? Never miss a post by getting them delivered direct to your mailbox whenever I create a new post. Don’t worry, you won’t get flooded with emails, I post at most once a week.
June 28, 2025 at 5:02 am
Great post! Thanks for sharing this.